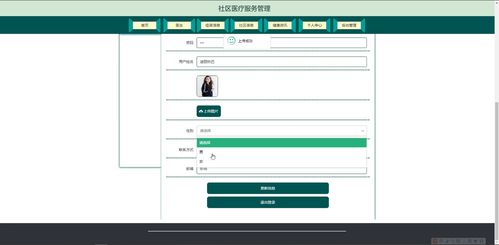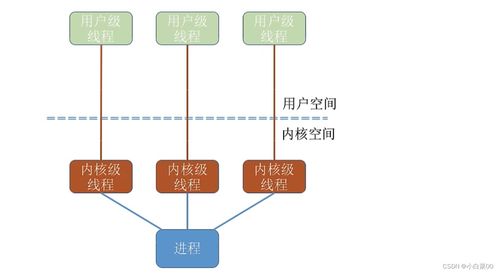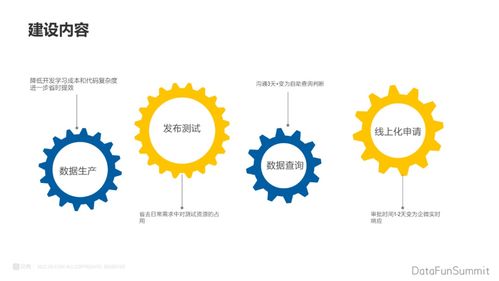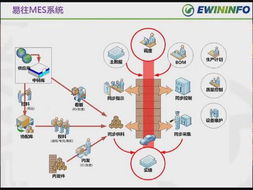
计算机视觉作为人工智能领域的重要分支,其知识体系构建离不开高效的数据处理流程。数据处理不仅是计算机视觉应用的基础,更是模型性能提升的关键环节。
数据采集是计算机视觉的起点。高质量的数据来源包括开源数据集、网络爬取、传感器采集等多种方式。以图像识别为例,数据采集需覆盖不同光照、角度、背景等变量,确保数据的多样性和代表性。
数据预处理环节包括图像清洗、格式统一和尺寸标准化。通过去除噪声图像、纠正扭曲、调整亮度和对比度等操作,可以显著提升后续分析的准确性。例如在目标检测任务中,标准化图像尺寸能够保证卷积神经网络的输入一致性。
数据增强技术是提升模型泛化能力的重要手段。通过旋转、缩放、裁剪、色彩变换等方法对原始数据进行扩充,可以有效防止过拟合。在深度学习模型中,适当的数据增强可以使模型在有限的数据集上获得更好的表现。
特征工程是数据处理的核心环节。在计算机视觉领域,这包括传统特征提取方法(如SIFT、HOG)和基于深度学习的特征表示。现代计算机视觉系统通常采用端到端的深度学习模型,自动学习图像的特征表示。
数据标注的质量直接影响监督学习的效果。在目标检测、语义分割等任务中,需要精确的边界框标注和像素级标注。随着主动学习技术的发展,智能标注系统能够显著提升标注效率。
数据管理包括数据存储、版本控制和隐私保护。在大规模计算机视觉应用中,需要建立完善的数据流水线,确保数据的可追溯性和安全性。特别是在医疗影像、自动驾驶等敏感领域,数据隐私保护尤为重要。
数据处理贯穿计算机视觉应用的整个生命周期。从数据采集到最终部署,每一个环节都需要精心设计和优化。随着人工智能技术的不断发展,数据处理方法也在持续演进,为计算机视觉的进步提供坚实的数据基础。