在数据驱动的时代,专业的数据科学程序员是连接原始数据与商业洞察的关键桥梁。数据处理作为数据科学流程中至关重要的一环,其能力直接决定了后续分析、建模与决策的质量。要成为一名精通数据处理的专业人士,需要构建一个坚实且全面的技能矩阵,这不仅包括技术硬实力,也涵盖思维软实力。
扎实的编程与工具能力是基础。熟练掌握至少一门核心数据处理语言至关重要,其中Python凭借其Pandas、NumPy等强大的库生态系统,已成为行业事实上的标准;R语言则在统计分析和可视化方面有独特优势。SQL是访问和操作关系型数据库的必备技能,必须精通复杂的查询、连接和聚合操作。熟悉大数据处理框架如Apache Spark(特别是PySpark)以应对海量数据,以及掌握数据可视化工具(如Matplotlib、Seaborn、Plotly或Tableau)来初步探索和呈现数据,都是不可或缺的。
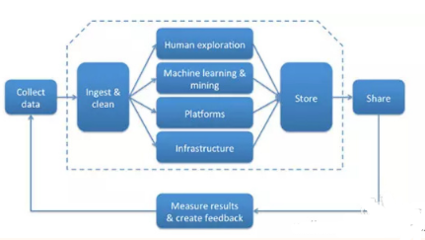
深刻理解数据处理的核心流程与方法论。这包括:
- 数据获取与加载:能够从多样化的源头(数据库、API、日志文件、网页、云存储)高效获取数据。
- 数据清洗与预处理:这是数据处理中最耗时但最关键的部分。需要具备识别并处理缺失值、异常值、重复数据的能力,精通数据格式转换、标准化、归一化以及特征编码(如独热编码)等技术。
- 数据集成与转换:能够将来自不同来源、格式各异的数据进行合并、连接和重塑,为分析准备好统一的数据集。
- 数据探索性分析(EDA):利用统计摘要和可视化技术,理解数据的分布、关系和潜在模式,为后续的特征工程和建模提供方向。
强大的问题解决与逻辑思维是灵魂。数据处理绝非机械操作。面对混乱的原始数据,需要能够抽象问题,设计清晰、高效且可复现的数据处理流水线。这要求程序员具备严谨的逻辑,对数据质量有敏锐的嗅觉,并能不断优化代码的性能和可维护性。理解数据背后的业务场景,能够确保数据处理工作服务于最终的商业或研究目标。
版本控制与协作能力是现代工程实践的标配。熟练使用Git进行代码和数据处理脚本的版本管理,是团队协作和项目可追溯性的基础。遵循良好的编码规范,撰写清晰的文档和注释,能让你的工作成果更容易被他人理解和复用。
持续学习与好奇心是永恒的动力。数据技术的生态日新月异,新的工具、库和最佳实践不断涌现。数据所在的业务领域知识也至关重要。一名顶尖的数据科学程序员,必须保持学习的热情,不仅深耕技术,也努力理解数据背后的行业逻辑。
专业的数据科学程序员在数据处理领域,应是一位集技术专家、问题解决者和业务沟通者于一身的复合型人才。构建从工具到思维,从技术到协作的完整能力栈,是驾驭数据海洋、挖掘其核心价值的坚实航船。